


Why Data Cloud Success Starts Long Before Activation
Salesforce Data Cloud is often introduced as a transformative platform. Connect your systems. Unify customer data. Activate intelligence in real time. The promise is compelling, and rightly so. But the narrative frequently skips the most critical prerequisite: data readiness.
Data Cloud does not operate in isolation. It ingests, harmonizes, and activates what already exists. That means every inconsistency, ambiguity, duplication, and governance gap embedded in your Salesforce org becomes part of the intelligence layer. Not later. Immediately.
Organizations that struggle with Data Cloud rarely fail because of the platform itself. They fail because they treat data preparation as a downstream task instead of a foundational discipline. Data Cloud magnifies both clarity and chaos. If your underlying data model is brittle, activation accelerates breakdown rather than value.
The most successful Data Cloud initiatives begin months earlier with a deliberate focus on data foundations. Not tooling. Not dashboards. Structure, semantics, and stewardship.
Understanding Salesforce Data Cloud and Its Expectations
Salesforce Data Cloud is designed to unify structured and semi-structured data from Salesforce and external systems into a real-time customer graph. It is engineered for scale, velocity, and AI-driven activation, enabling organizations to move beyond static reporting into continuous, data-powered decision-making. The architecture is optimized to ingest large volumes of data, reconcile identities across sources, and make that data immediately usable for personalization, automation, and intelligence.
But there is an important nuance that is often overlooked.
Salesforce Data Cloud assumes a certain level of organizational and data maturity before it ever delivers value.
It expects your Salesforce environment to behave predictably.

That expectation shows up in very practical ways.
It expects stable object relationships, where core entities like Accounts, Contacts, Leads, and custom objects have clear, intentional relationships that have not been bent repeatedly to serve short-term needs. When relationships are overloaded, duplicated, or loosely defined, the customer graph becomes harder to reconcile and less trustworthy.
It expects clearly defined identifiers, not just technically unique fields, but identifiers that are consistently populated, standardized, and trusted across systems. Email, phone, external IDs, and customer keys must behave as identifiers, not as optional attributes that change meaning by team or process.
It expects consistent field semantics, where a field represents the same business concept everywhere it is used. A “status” field should not silently shift meaning between sales stages, lifecycle phases, and support states. Data Cloud cannot infer intent where humans never aligned on definition.
It expects governed access controls, with deliberate decisions around who can see, modify, and activate data. As data becomes more centralized and more powerful, ambiguity in permissions turns into operational risk, not just administrative inconvenience.
And it expects predictable data behavior under load, meaning automations, validations, and integrations continue to function reliably when volumes increase, updates happen concurrently, and data moves closer to real time. What works acceptably in low-volume, batch-driven environments often breaks when velocity increases.
If your Salesforce org evolved organically through years of custom objects, tactical automation, inherited integrations, and team-specific workarounds, these assumptions may not hold. Most mature orgs did not design their data model with Data Cloud in mind. They designed it to solve immediate business problems. Over time, layers were added. Exceptions were introduced. Temporary solutions became permanent.
In that context, Data Cloud does not simplify complexity by default. It exposes it.
Faster, because ingestion and activation reduce the time between data creation and impact.
Louder, because inconsistencies surface across dashboards, AI outputs, and customer experiences.
Across more stakeholders, because data issues are no longer confined to admins or analysts but affect marketing, sales, service, and leadership simultaneously.
This is not a flaw in Data Cloud. It is a signal.
Understanding this expectation gap early is what separates successful Data Cloud initiatives from disappointing ones. When teams recognize that Data Cloud is a multiplier, not a repair tool, they approach adoption differently. They invest in clarity before connectivity. They stabilize before they activate.
That awareness alone can save months of rework, prevent loss of trust, and turn Data Cloud from a technical rollout into a strategic advantage.
The Myth of “We’ll Clean Data Later”
“We’ll fix it after ingestion” is one of the most expensive assumptions teams make, not because it is technically wrong, but because it misunderstands how interconnected modern data systems have become.
Once Salesforce Data Cloud is live, data no longer lives in neat, isolated silos. It moves. It activates. It informs decisions in near real time. At that point, every data issue stops being a local inconvenience and starts becoming a systemic risk.
A single malformed field is no longer just a reporting annoyance. It can distort identity resolution logic, causing multiple customer profiles to merge incorrectly or remain fragmented when they should be unified. A duplicate record no longer affects one object or one team. It skews segmentation, inflates audience sizes, and leads to inconsistent customer experiences across channels. An inconsistent value that once required a quiet admin fix now feeds AI models, influencing predictions, recommendations, and automated actions.
When cleanup is deferred until after ingestion, the work shifts from intentional improvement to reactive firefighting across interconnected systems.
The cost of correction multiplies for several reasons.
First, data is already activated downstream. By the time an issue is discovered, it may already be powering journeys, automations, dashboards, and customer-facing experiences. Fixing the data does not automatically undo the actions it triggered. Teams must diagnose impact, roll back decisions, and explain outcomes after the fact.
Second, AI models are trained on flawed history. Machine learning does not forget easily. If inaccurate, inconsistent, or incomplete data becomes part of a training set, the resulting models carry those biases forward. Correcting the source data later often requires retraining models, revalidating outputs, and rebuilding trust in predictions that stakeholders have already seen fail.
Third, trust is eroded among users. When insights contradict lived experience, adoption stalls. Sales teams question recommendations. Marketing teams doubt segments. Leadership hesitates to rely on forecasts. Once confidence is lost, even correct data struggles to regain credibility.
Fourth, governance decisions become political. After activation, data issues are visible to more teams, each with different priorities. Fixes that were once technical become cross-functional negotiations. Ownership becomes contested. Urgency replaces clarity, and decision-making slows precisely when speed is needed most.
Cleaning data later is not impossible. Many organizations do it. But it is slower, riskier, and far more disruptive than addressing foundational issues upfront. Every fix must now account for downstream dependencies, historical impact, and organizational perception.
Mature organizations reverse this logic entirely. They treat data stabilization as a prerequisite, not a phase. They fix structure before flow. They establish trust before activation. By stabilizing first and scaling second, they turn Data Cloud from a source of amplified complexity into a platform for confident, sustained growth.
What a “Clean Data Foundation” Really Means in Salesforce
Clean data is often reduced to surface-level hygiene metrics. Fewer duplicates. Fewer null values. More validation rules. Cleaner dashboards.
Those indicators are easy to measure, which is why they are often mistaken for completeness.
That definition, however, is insufficient.
A truly clean data foundation is not defined by how tidy data looks in isolation, but by how reliably it behaves when the business places real demands on it. It is structural. It is semantic. And most importantly, it is operational.

A clean data foundation means:
Objects exist for a clear business purpose
Every object in the Salesforce org should answer a simple question: what business decision or process does this object support? Over time, many orgs accumulate custom objects created to solve short-term needs, pilots, or edge cases. When those objects outlive their purpose, they introduce ambiguity into the data model. A clean foundation requires periodic object rationalization, ensuring that each object has a defined role, a clear owner, and a reason to exist within the broader architecture.
Fields have a single, documented meaning
Fields should not rely on tribal knowledge. When a field’s meaning is inferred rather than defined, interpretations drift. One team uses it as a status. Another treats it as a lifecycle indicator. A third repurposes it entirely. Clean data requires explicit documentation, enforced usage, and retirement of fields that have lost semantic clarity. One field. One meaning. Everywhere.
Data flows behave consistently over time
Clean data is predictable. Automations, integrations, and user actions should produce the same outcomes today as they do tomorrow under the same conditions. When data behaves differently depending on timing, volume, or entry point, downstream systems cannot trust it. Consistent behavior is achieved by simplifying automation logic, reducing overlapping rules, and validating integrations under realistic load scenarios.
Ownership is explicit, not assumed
Data quality deteriorates fastest where ownership is unclear. Every critical object and dataset must have an accountable owner responsible for definition, quality, and change decisions. Without ownership, issues linger, fixes are delayed, and governance becomes reactive. Explicit ownership turns data from a shared problem into a managed asset.
Quality controls are enforced by design
Guidelines are not enough. Clean data foundations rely on structural enforcement. Validation rules aligned with business logic. Controlled picklists instead of free text. Guardrails that prevent bad data from entering the system in the first place. Quality controls embedded into system design reduce dependence on user discipline and post-entry cleanup.
Ultimately, clean data is less about visual neatness and more about operational reliability. It is not about how data looks in a spreadsheet, but how it performs inside real workflows. Clean data behaves predictably under pressure. It scales without distortion. It supports automation, analytics, and AI without constant exception handling.
Most importantly, it does not surprise downstream systems.
Data Accuracy: Eliminating Errors at the Source
Accuracy begins at entry points. Not dashboards.
In Salesforce orgs, inaccurate data often originates from:
- Overly permissive manual entry
- Legacy integrations pushing malformed values
- Automation overwriting trusted fields
- Inconsistent API mappings
Over time, teams adapt to inaccurate data instead of correcting it. They add filters. They build workarounds. They stop trusting certain fields entirely.
Before Data Cloud adoption, accuracy must be re-established structurally:
- Tighten validation rules aligned to business logic
- Reduce free-text fields where structured input is required
- Audit integrations for silent failures
- Remove conflicting automations
Accuracy is not a reporting exercise. It is a design decision.
Data Consistency: Standardizing Definitions Across Teams
One field with multiple interpretations is a silent killer of analytics and AI.
“Customer Type,” “Account Status,” “Lifecycle Stage.” These fields often mean different things to Sales, Marketing, and Support. Everyone believes they are right. The system quietly disagrees.
Data Cloud cannot reconcile philosophical disagreement. It can only process what it receives.
Consistency requires intentional alignment:
- Shared data dictionaries
- Explicit field descriptions
- Deprecated fields clearly marked and retired
- Cross-functional agreement on semantics
Consistency enables trust. Trust enables adoption.
Data Completeness: Closing the Gaps That Break AI Insights
Incomplete data rarely fails loudly. It biases quietly.
Missing fields distort segmentation. They skew predictive models. They create blind spots that are difficult to detect because nothing technically “breaks.”
Completeness requires:
- Identifying fields critical to downstream use cases
- Measuring fill rates longitudinally, not just snapshots
- Fixing upstream process gaps, not mass updates
If users cannot or will not populate a field, the problem is rarely user discipline. It is process design.
Data Timeliness: Why Stale Data Is Worse Than No Data
Stale data undermines relevance.
Data Cloud enables real-time personalization and orchestration. But if upstream systems update hours or days later, activation becomes misleading rather than helpful.
Timeliness issues often stem from:
- Batch-based integrations
- Manual update dependencies
- Latency hidden by dashboards
Before adoption, teams must evaluate:
- Integration frequency
- Latency tolerance by use case
- Error handling when updates fail
Data that arrives too late is functionally incorrect.
Data Deduplication: Preparing Identity Resolution for Scale
Identity resolution is powerful, but it is not magic.
If duplicates persist upstream, Data Cloud surfaces conflicts faster than teams can resolve them. Matching rules become brittle. Confidence erodes.
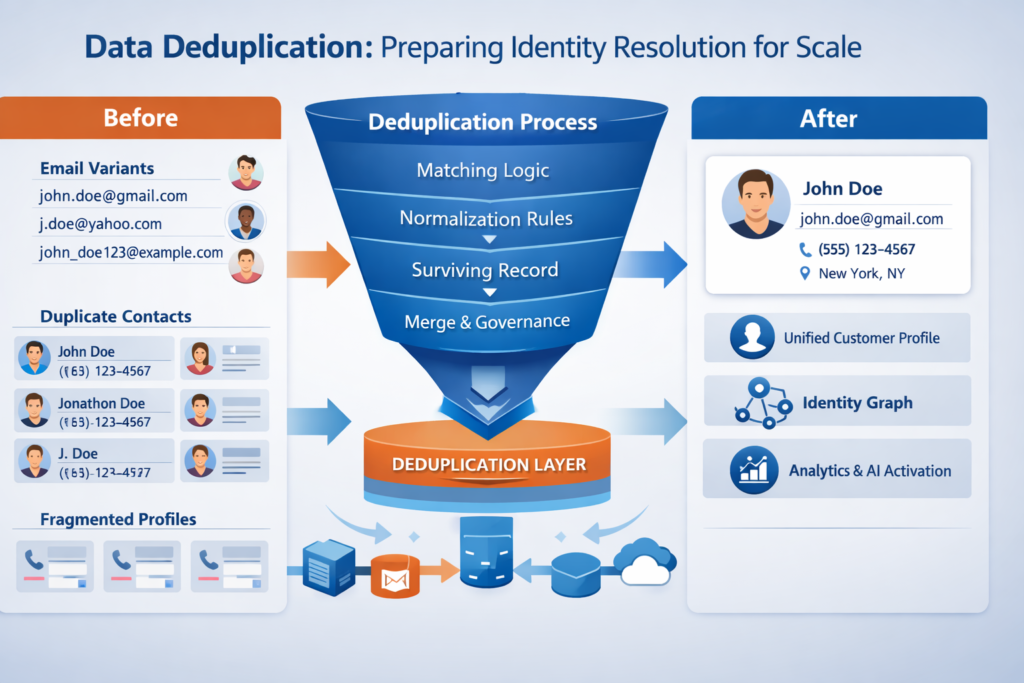
Pre-Data Cloud deduplication involves:
- Standardizing identifiers (email, phone, external IDs)
- Rationalizing matching logic
- Eliminating shadow records created by integrations
- Establishing a clear master record strategy
Identity resolution performs best when ambiguity is minimized before ingestion.
Data Governance: Ownership, Accountability, and Control
Data without ownership decays predictably.
Governance is not about committees. It is about clarity.
Effective governance defines:
- Who owns which objects
- Who approves schema changes
- How exceptions are handled
- How quality is monitored
Without governance, every data issue becomes an argument. With governance, it becomes a process.
Object and Field Rationalization Before Data Cloud Ingestion
Most Salesforce orgs carry historical baggage:
- Custom objects created for one-time needs
- Fields added “just in case”
- Parallel data models solving the same problem
Data Cloud amplifies this clutter.
Rationalization involves:
- Removing unused fields
- Merging overlapping objects
- Simplifying relationships
Signal improves when noise is removed.
Master Data Management in a Salesforce Context
Salesforce often acts as both a system of record and engagement. That duality creates ambiguity.
Before Data Cloud:
- Define authoritative systems for key entities
- Establish conflict resolution rules
- Prevent circular updates
Master data ambiguity undermines every activation use case.
Preparing Data for Real-Time and Near Real-Time Use Cases
Real-time data changes expectations.
Automations designed for batch updates may fail under concurrency. Validation rules may block flows. API limits may surface unexpectedly.
Stress-testing is essential:
- High-volume scenarios
- Concurrent updates
- Error handling under load
Design for velocity before velocity is demanded.
Security, Compliance, and Trust Boundaries
Data Cloud expands visibility. Expansion without control creates risk.
When data is unified and activated across teams, channels, and systems, the blast radius of a security or compliance misstep increases dramatically. What was once a contained exposure inside a single Salesforce object can become an enterprise-wide issue once data is centralized, harmonized, and made actionable in near real time.
Salesforce Data Cloud does not weaken security by default. But it assumes that trust boundaries are already well defined. If they are not, Data Cloud simply makes the gaps visible faster and to more people.
Preparation must therefore treat security and compliance as foundational design elements, not post-ingestion checks.
That preparation includes several critical dimensions.
Reviewing field-level security
Field-level security is often configured incrementally over time, responding to immediate access requests rather than long-term exposure risk. Before Data Cloud adoption, every sensitive field should be reviewed with intent. Who truly needs read access? Who should never see this value once data is activated beyond Salesforce core? Data Cloud activation surfaces fields in analytics, segmentation, and AI contexts where over-permissive access becomes a liability, not a convenience.
Auditing sharing models
Record-level access rules that function acceptably within Salesforce may not scale cleanly when data is unified and reused across use cases. Complex, exception-heavy sharing models increase the risk of unintended visibility once data moves into broader activation layers. Auditing sharing logic ensures that access patterns remain intentional and understandable when data is no longer consumed only by transactional users.
Validating consent markers
Consent fields are only as reliable as their enforcement. In many orgs, consent exists as a checkbox that is inconsistently populated, poorly governed, or silently bypassed by integrations. Before Data Cloud ingestion, consent indicators must be standardized, clearly defined, and reliably updated. Activation without trustworthy consent logic exposes organizations to regulatory risk and reputational damage.
Segmenting sensitive attributes
Not all data deserves equal exposure. Personally identifiable information, financial details, health-related attributes, and internal risk indicators should be deliberately segmented. Data Cloud allows powerful activation, but sensitive attributes must be isolated, masked, or excluded from certain use cases by design. Segmentation preserves analytical value without expanding risk unnecessarily.
The underlying principle is simple but unforgiving: security gaps scale faster than security fixes.
Once data is activated across systems, correcting overexposure requires unwinding live use cases, retraining models, revalidating compliance, and restoring stakeholder trust. Each step is slower and more complex than designing proper boundaries upfront.
Organizations that succeed with Data Cloud treat security, compliance, and trust not as constraints, but as enablers. Clear boundaries create confidence. Confidence accelerates adoption. And adoption is where Data Cloud delivers its real value.
Designing for AI Readiness, Not Just Reporting
AI models demand more than clean reports.
They require:
- Historical continuity
- Outcome-linked features
- Stable field behavior
Data designed only for operational reporting may fail predictive use cases. AI readiness begins with intentional data modeling.
Aligning Business Outcomes With Data Models
One of the most subtle but damaging failure modes in Data Cloud initiatives is treating the platform as an exploratory playground. Teams ingest data, build unified profiles, and generate insights without a clear answer to a fundamental question: what will we do differently because this data exists?
Without that clarity, Data Cloud becomes impressive but inert.
High-performing organizations anchor Data Cloud adoption to outcomes, not possibilities. They start by defining what must change in the business, then design the data foundation to support those changes.
That definition begins with three anchors.
Decisions to improve
Every organization makes decisions repeatedly. Which leads to prioritize. Which accounts need attention. Which customers are at risk. Data Cloud should improve the quality, speed, or confidence of those decisions. If a decision cannot be named, measured, and owned, it does not justify ingestion. Data that does not inform a decision adds cognitive load without value.
Actions to automate
Insight without action is insight wasted. Data Cloud excels when it powers automation that removes latency from execution. Triggering outreach. Adjusting prioritization. Routing work. Personalizing timing. Defining the actions that should happen automatically forces teams to think in operational terms, not analytical abstraction. It also sets clear requirements for data freshness, accuracy, and governance.
Experiences to personalize
Personalization is not about novelty. It is about relevance. Data Cloud should enable experiences that feel timely, contextual, and coherent across channels. That requires a deliberate understanding of which attributes truly matter to the customer experience and which are incidental. Personalization goals sharpen ingestion decisions and prevent bloated customer profiles that no one actually uses.
Once decisions, actions, and experiences are defined, the direction of design reverses.
Instead of asking what data can we ingest?, teams ask what data is required to achieve this outcome? They map backward from business goals to data sources, fields, and transformations. Anything that does not support an outcome is deferred or excluded.
This backward mapping discipline prevents two common failures at once. It avoids over-ingestion, where excess data increases complexity without benefit. And it prevents under-utilization, where valuable data exists but is never operationalized.
When Data Cloud is designed around outcomes rather than curiosity, it becomes not just a data platform, but a decision engine.
Common Data Foundation Mistakes That Derail Data Cloud Projects
Most Data Cloud projects that stall or underdeliver do not fail because of technology limitations. They fail because the same foundational mistakes repeat, often driven by urgency, excitement, or pressure to show quick wins.
These patterns recur across industries and org sizes.
Ingesting everything “just in case”
One of the most common impulses is to connect every available data source and ingest every field simply because Data Cloud can handle it. The logic sounds reasonable. More data should mean more insight. In practice, indiscriminate ingestion creates noise faster than it creates value. Unused fields complicate identity resolution, increase governance overhead, and slow down activation. Without a clear use case, extra data becomes a liability. Mature teams ingest intentionally, starting with the minimum data required to support defined outcomes.
Ignoring upstream process flaws
Data Cloud often becomes the place where long-standing process issues finally surface. Inconsistent data entry, broken handoffs between teams, and fragile integrations are not caused by Data Cloud. They predate it. Treating Data Cloud as the fix rather than the amplifier leads to frustration. If upstream processes produce unreliable data today, ingestion simply spreads that unreliability more widely and more quickly.
Over-relying on identity resolution
Identity resolution is powerful, but it is not a substitute for clean source data. Matching rules cannot compensate for missing identifiers, inconsistent formatting, or conflicting record strategies. When teams assume identity resolution will “figure it out,” they postpone necessary cleanup and standardization. The result is partial matches, false merges, and fragmented customer views that undermine trust in the platform.
Treating governance as temporary
Governance is often approached as a phase. Define rules, document decisions, move on. That mindset fails as soon as data volume, velocity, or use cases expand. Data Cloud increases the importance of governance because more teams depend on shared data assets. When governance is treated as temporary, quality decays, exceptions multiply, and decision-making becomes reactive.
All of these mistakes stem from the same root cause: urgency without discipline.
The desire to move fast is understandable. Data Cloud promises rapid activation and visible impact. But without a disciplined foundation, speed amplifies fragility instead of value. Teams that slow down long enough to design intentionally move faster in the long run, with fewer reversals, fewer trust issues, and far more sustainable outcomes.
A Practical Roadmap to Build a Clean Data Foundation
A sustainable sequence:
- Audit current data health
- Define priority use cases
- Rationalize schema
- Fix upstream processes
- Establish governance
- Measure readiness
- Activate Data Cloud
Order matters.
Measuring Readiness Before You Turn Data Cloud On
Readiness is measurable:
- Duplicate rates
- Field completeness
- Latency metrics
- Ownership coverage
If these metrics fluctuate, activation will too.
What Changes After Data Cloud Goes Live
After activation:
- Data issues surface faster
- Cross-team dependencies increase
- Governance becomes visible
Strong foundations adapt smoothly. Weak ones react constantly.
Why Data Foundation Is a Continuous Discipline
Data quality is not a phase. It is an operating model.
New systems, new products, and new regulations continuously reshape requirements. Stewardship must evolve with them.
Conclusion: Building for Scale, Intelligence, and Trust
Salesforce Data Cloud is a multiplier. It accelerates whatever exists.
Organizations that invest in clean data foundations activate faster, trust insights more deeply, and scale AI responsibly.
At CloudVandana, teams help organizations prepare Salesforce data for Data Cloud, AI, and Agentforce initiatives through structured audits, governance design, remediation, and readiness frameworks.
If Data Cloud is on your roadmap, preparation determines outcome. The best time to build your foundation is before activation begins.
Frequently Asked Questions (FAQs)
1. Do we need perfect data before adopting Data Cloud?
No. You need reliable, governed, and well-understood data.
2. Can Data Cloud clean data automatically?
It can harmonize and resolve identities, but upstream quality still matters.
3. How long does data foundation preparation take?
Typically several weeks to a few months, depending on complexity.
4. Should cleanup happen inside Salesforce or externally?
Primarily at the source, inside Salesforce and upstream systems.
5. Is governance mandatory before adoption?
Practically, yes. Without it, quality degrades quickly.
6. Who should own data foundation work?
Cross-functional teams spanning IT, Sales, Marketing, Service, and Compliance.
7. Is this relevant for small orgs?
Yes. Smaller orgs benefit the most by avoiding future rework.
8. How does clean data impact AI accuracy?
It directly improves prediction reliability and trust.
9. What is the biggest risk of skipping preparation?
Loss of confidence in insights and stalled adoption.
10. Can preparation happen in parallel with rollout?
Yes, but foundational issues must be addressed before critical use cases go live.
11. How often should readiness be reassessed?
Continuously, with formal reviews at least quarterly.
12. Where should overwhelmed teams start?
With a focused data audit tied to one high-impact Data Cloud use case.

Atul Gupta is CloudVandana’s founder and an 8X Salesforce Certified Professional who works with globally situated businesses to create Custom Salesforce Solutions.
Atul Gupta, a dynamic leader, directs CloudVandana’s Implementation Team, Analytics, and IT functions, ensuring seamless operations and innovative solutions.
YOU MIGHT ALSO LIKE

The Future of Marketing Automation with Agentforce Marketing

What is Salesforce CRM – Complete Guide for Businesses

Salesforce Financial Services Cloud: The Complete Guide for Modern Financial Institutions

Lightning Platform (UI & Development): A Practical Guide

What Does a Salesforce Partner Actually Do? A Complete Guide for Businesses





